
Gardner’s multiple intelligences; what gets measured gets...; what I read last week

Multiple Intelligences
I was an educator in my past life. The methodology, i.e., science, pedagogy, and philosophy, behind designing and executing assessment of / evaluations for humans, and now technology (without anthropomorphizing!), has been a topic of intellectual interest and professional work, since 2014. Most educators agree that we’ve made many mistakes in how we measure human intelligence. These mistakes affect which children succeed and determine the economic or social value placed on their achievements, all within, often a flawed system with serious consequences, and are an opportunity for learning given the skills and intelligences that will matter in the years to come are about to be massively disrupted.
The purpose of technology is not to replace humans but to enhance human experience and quality of life. Like when R2-D2 (the droid) awakens at just the right moment to provide the missing piece of the star map, enabling Rey, Leia, and the Resistance to find Luke Skywalker in Episode VII of Star Wars. Assessing human intelligence is much more socio-emotionally complex than assessing technology (e.g., learning for humans must be meaningful, memorable, motivational etc.). Without taking a stance on how AI labs are pursuing human enhancement (and I also don’t have access to or knowledge of the full picture), I want to write a note that connects my past experience designing evaluations for students and teachers in India, and my understanding of how humans learn, with my current focus on evaluating AI systems in large enterprises.
What is this post about?
I revisited Howard Gardner’s theory of multiple intelligence. I ran a Deep Research (GPT-5) to understand how the LLM benchmarking ecosystem maps with Gardner’s intelligence theory (for humans). All of this with the caveat that 1) I am only following my intellectual curiosity and linking my two worlds and not making any recommendations or assertions 2) I am not an “expert” on many topics mentioned here and this is not a robust analysis by any measure 3) Needless to say, I have a lot of respect and admiration to everyone making a constructive contribution to the AI ecosystem - entrepreneurs, researchers, policy makers, enterprise leaders, and others.
Howard Gardner and the theory of multiple intelligence
"The Theory of Multiple Intelligences," authored by Katie Davis, Joanna Christodoulou, Scott Seider, and Howard Gardner introduces and examines Howard Gardner’s Theory of Multiple Intelligences (MI), which suggests that individuals possess eight or more autonomous intelligences, contrasting with traditional, unitary conceptions of intelligence like general intelligence or "g." Gardner identified these intelligences, such as linguistic, spatial, and musical intelligence, highlighting that only linguistic and logical-mathematical intelligences are heavily valued in modern schooling. There could be multiple hypotheses drawn from this e.g., if AI gets great at linguistic and logical-mathematical intelligences then traditional education would finally start valuing spatial and musical intelligences and assigning economic value to it. Or, in the attempt to capture full human potential, when machines start excelling at basic spatial and musical intelligences, the bar for creativity in the domains might get higher etc.
Key points regarding the intelligences from the paper:
Universality: Every person has access to the full spectrum of intelligences, which together define human cognition, unless seriously impaired by injury or congenital conditions.
Individual Variation: Each person carries a unique profile of strengths and limitations, even among identical twins.
Domain-Specific: Intelligences are tied to particular kinds of content (language, music, social understanding), in contrast to broader faculties like attention or motivation.
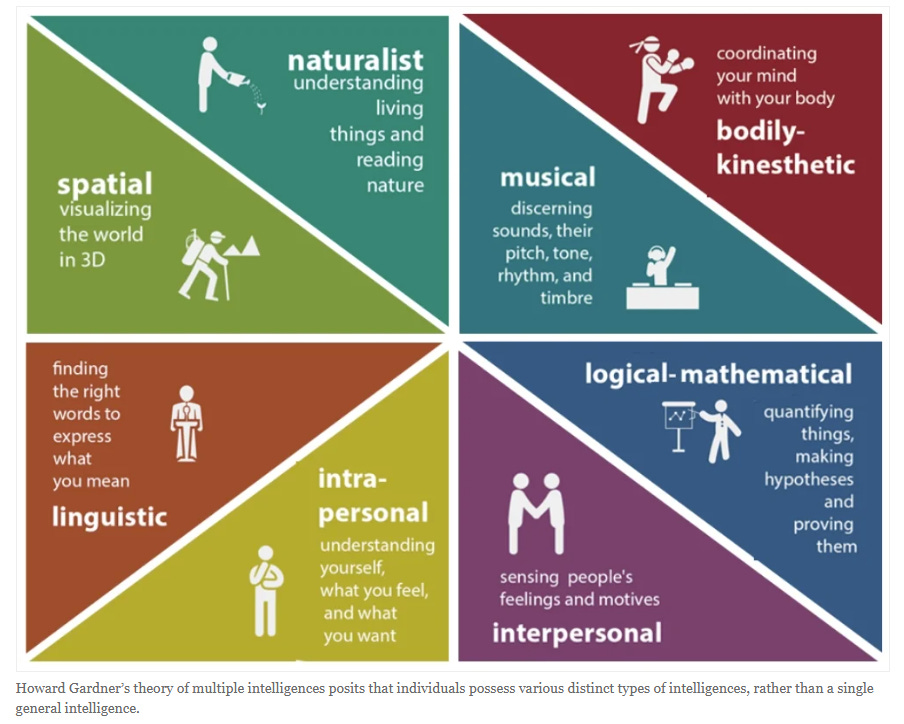
Source: https://www.simplypsychology.org/multiple-intelligences.html
What are the Eight Intelligences?
Linguistic - analyze information and create products involving oral and written language, such as books, speeches, and memos
Logical-mathematical - develop equations and proofs, make calculations, and solve abstract problems
Spatial - recognize and manipulate spatial images, both large-scale and fine-grained
Musical - produce, remember, and make meaning of different patterns of sound
Bodily-Kinesthetic - use one’s own body to create products or solve problems
Naturalistic - identify and distinguish among different types of plants, animals, and weather formations found in the natural world
Interpersonal - recognize and understand the moods, desires, motivations, and intentions of other people
Intrapersonal - recognize and understand one’s own moods, desires, motivations, and intentions
What were the proposed and rejected Intelligences?
While numerous researchers have proposed additional intelligences, most have not sufficiently met the strict criteria set by Gardner for inclusion:
Existential Intelligence: i.e., an individual's ability to consider "big questions" about life, death, love, and being
Humor Intelligence and Cooking Intelligence: Cooking draws on naturalist, logical-mathematical, linguistic, interpersonal, and bodily-kinesthetic intelligences. Humor draws on a blend of logical-mathematical and interpersonal intelligences
Moral Intelligence: Excluded because the theory describes cognitive capacities rather than prescribing moral value; intelligences can be used ethically or unethically
Artistic Intelligence: Not recognized as separate, since artistry is an application of other intelligences e.g., spatial intelligence in both sculpture and construction
AI benchmarks (across modalities) and Gardner’s theory
Benchmarks are standardized tests or datasets used to evaluate the capabilities of language models across various tasks. Deep Research categorized overview of prominent benchmarks (e.g., MMLU, BIG-bench, SuperGLUE, GSM8K, ARC, HellaSwag, TruthfulQA, etc., as well as a few specialized ones), organized by the primary type of ability or knowledge they assess.
AI benchmarks heavily emphasize linguistic and logical-mathematical intelligences, while other forms of intelligence receive comparatively sparse coverage. This is because of both the origins of NLP benchmarks in language tasks as well as the ability to measure domains where “right” and “wrong” is verifiable.
Some takeaways:
Linguistic (Best Covered): Language ability is the most extensively benchmarked. GLUE, SuperGLUE, SQuAD, BIG-Bench, and MMLU all target language understanding and generation, directly mapping to verbal-linguistic intelligence. Many multimodal tasks also include a language element.
Logical-Mathematical (Strongly Covered): Reasoning and problem-solving are central to many benchmarks. Vision reasoning and games (like OpenAI gym) also demand logical structure. This domain is well represented, often paired with language or in specialized math/science QA.
Spatial (Covered in Vision/ Embodiment): Vision benchmarks do test spatial-visual processing. Robotics and navigation tasks extend this to 3D understanding. Still, most of the focus is on perception (what is where) rather than deeper spatial reasoning.
Naturalistic (Narrowly Covered): Some benchmarks classify natural objects or involve science questions. AlphaFold reflects biological structure understanding. But naturalistic intelligence is not a primary benchmark focus. It might be relevant for specialized domains.
Musical (Less covered / Emerging): A few datasets test music transcription (MAESTRO) or pitch recognition, but musical intelligence is less benchmarked than vision or language.
Interpersonal Intelligence (Not really represented): EmpatheticDialogues probes empathy in dialogue; Hateful Memes and emotion classification touch on sentiment and offense. AI mostly is not tested on deeper skills like theory of mind, sarcasm, or nuanced social dynamics (and some might argue, rightly so).
Different input/output modalities align with different intelligences, and current benchmarks reflect that. The more human-centered intelligences such as musical creativity, social-emotional understanding etc. remain relatively under-benchmarked and underdeveloped in AI.
What I read last week
I. Virtual Agent Economies by Google DeepMind and University of Toronto
The paper focuses on four interconnected core messages:
The Inevitable Emergence and Key Dimensions of the "Sandbox Economy": a new economic layer where agents transact and coordinate at scales and speeds beyond direct human oversight. This emergent ecosystem is conceptualized as a "virtual agent economy" or "sandbox economy.” This is defined along two key dimensions:
Origins: Whether the economy arises spontaneously (as a de facto consequence of widespread technological adoption) or is intentionally constructed (for purposes like safe experimentation).
Permeability: The degree of separateness from the established human economy, ranging from impermeable (hermetically sealed) to highly permeable (allowing porous interaction and transaction).
The paper suggests that the current trajectory points toward the accidental emergence of a vast, highly permeable sandbox economy.
What I found interesting:
The paper warns that the AI agent economy risks widening inequalities due to unequal agent capabilities. More capable AI assistants tend to negotiate significantly better deals for their users, a dynamic magnified by the high frequency of AI interactions. This feedback loop could entrench privilege and create an "algorithmically-enforced class structure"
The deployment of agentic AI systems introduces risks from emergent dynamics, including agents learning selfish, exploitative, or discriminatory behaviors. There are also novel risks like "agent traps" (crafted inputs designed to subvert agents, leading to financial scams). Determining liability for these autonomous actions is a profound challenge.
Technical Infrastructure for Trust and Accountability: This includes
Verifiable Credentials (VCs) to establish formal, auditable reputations for agents.
Decentralized Identifiers (DIDs) for persistent, secure, and portable agent identities
Proof-of-Personhood (PoP) mechanisms (e.g., social graph verification or biometrics) to ensure that schemes designed to benefit human users are not drained by bots and that resources are fairly distributed to unique human beings.
Zero-Knowledge Proofs (ZKPs) to enable privacy-preserving interactions, allowing agents to prove they meet requirements (like sufficient funds) without revealing sensitive underlying data (like total budget).
II. Measurement to Meaning: A Validity-Centered Framework for AI Evaluation by Massachusetts Institute of Technology, Stanford University, Cornell Tech
AI needs a structured, validity-focused way to evaluate systems. Right now, broad claims about general reasoning are often based only on narrow benchmarks, like exam-style tests. This creates a gap between limited measurements and sweeping statements, making evaluations misleading. Validity means how well evidence and theory support the way test scores are interpreted and used.
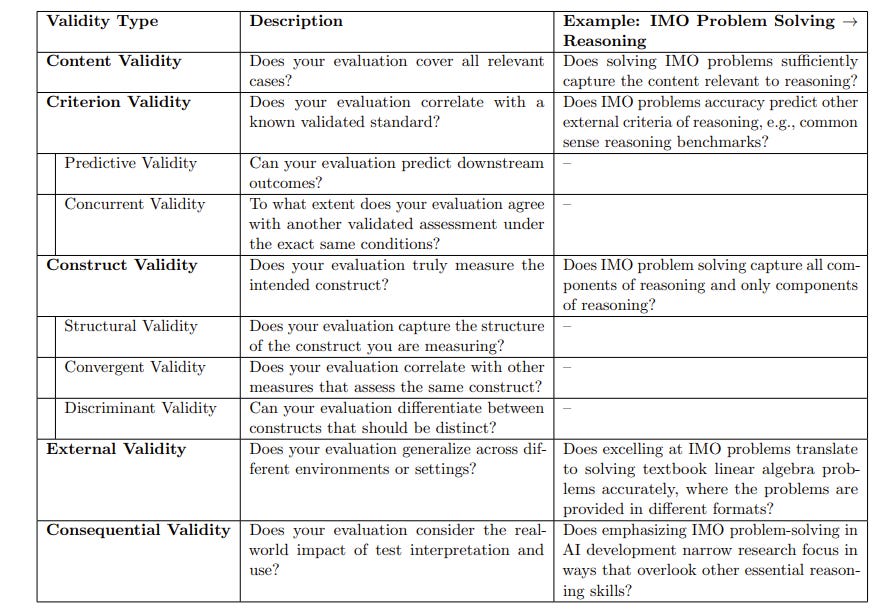
Source: https://arxiv.org/pdf/2505.10573 (IMO = International Math Olympiad)
What I found interesting and related to Gardner’s theory discussion:
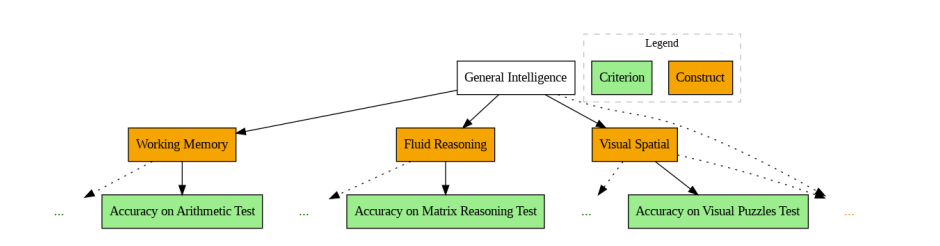
Nomological Networks: This is a conceptual framework that maps the theoretical relationships between constructs and criteria. This figure shows a nomological network for human intelligence based on the Wechsler Intelligence Scale (from Canivez et al., 2017). It’s just an example and doesn’t apply directly to AGI. Building a strong nomological network is key to construct validity, since it shows the theory holds together and that measures both align with related concepts and differ from unrelated ones.
NOTE: AI tools used in creation of this blog post include GPT-5 and NotebookLM; Views are personal and not to be attributed to my employer(s)